SISTEMA DE RECONOCIMIENTO ÓPTICO DE CARACTERES (OCR) CON REDES NEURONALES
José R. Hilera González, Juan P. Romero Villaverde, José A. Gutiérrez de Mesa
Departamento de Ciencias de la Computación
Universidad de Alcalá de Henares
28871 Alcalá de Henares
Fax: 885 48 04 E-mail: mthilera@alcala.es
RESUMEN.- Los sistemas que, a partir de un texto escrito o impreso en papel o similar, crean un fichero de texto en un soporte de almacenamiento informático, se denominan Sistemas de OCR (Optical Character Recognition), o de Reconocimiento Óptico de Caracteres. En esta ponencia se presenta un sistema OCR con la característica de poder "aprender", mediante una red neuronal, patrones de caracteres que representen las posibles variaciones (tamaño, tipo de letra) de la forma de los diferentes caracteres impresos que pueden aparecer en los documentos para, en el futuro y con la misma red, poder "reconocerlos" y realizar la conversión del texto escrito en papel a texto almacenado en un fichero ASCII.
Palabras claves: OCR, Redes Neuronales, Reconocimiento de Formas, Backpropagation.
1 INTRODUCCIÓN
Cuando se dispone de información en forma de documento impreso y se desea procesarla mediante un computador, existen dos opciones: una primera consistiría en introducirla a través del teclado, labor larga y tediosa. Otra posibilidad es automatizar esta operación por medio de un sistema de OCR compuesto de un software y hardware adecuado que reduciría considerablemente el tiempo de entrada de datos. En nuestro caso, el hardware utilizado se reduce a un dispositivo de captura de imágenes (escáner) y a un computador personal en el que se ejecuta el software de reconocimiento desarrollado a tal efecto.
El objetivo final del sistema es la generación de un fichero con los códigos ASCII correspondientes a los caracteres de un texto en papel cuya imagen ha sido previamente capturado mediante el escáner. Se trata, en definitiva, de un caso particular de Sistema de Reconocimiento Automático de Formas [1] que, por tanto, consta de una etapa de aislamiento de los objetos a reconocer (en este caso caracteres impresos), otra de extracción de sus características individuales y finalmente la aplicación de una función discriminante que permita establecer la clase a la que pertenece cada objeto (en este caso la clase de carácter, que estará representada por su correspondiente código ASCII).
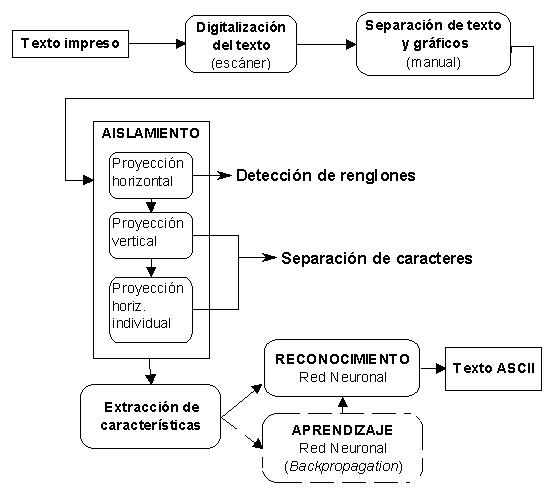
En la figura 1 se muestran con mayor detalle las fases implicadas en el sistema OCR desarrollado. En primer lugar se obtiene la imagen digitalizada del documento impreso en forma de mapa de bits procedente del escáner (aunque también existe la posibilidad de utilizar un módem o fax). Esta imagen tiene estructura de matriz bidimensional, cuya magnitud vendrá dada en función del tamaño y la resolución de la digitalización. Por ejemplo para una página de tamaño DIN-A4 digitalizada a 300 puntos por pulgada (d.p.i) genera una matriz aproximadamente de 1MB. En nuestro caso, el sistema OCR trabaja con imágenes con el formato estándar TIFF (Tag Image File Format), diseñado conjuntamente por Microsoft y Aldus con el objetivo de estandarizar los formatos gráficos utilizados en el entorno de autoedición. En [2] puede encontrarse una descripción detallada de este formato.
Figura 1.- Etapas del Sistema OCR desarrollado
Si la imagen contiene tanto texto como gráficos, se procede a separarlos antes de realizar cualquier otra operación. En nuestro caso, esta separación es manual mediante la selección, con el "ratón" del computador, de las áreas de interés en el documento.
Después de este procesamiento previo de la imagen, se procede al aislamiento de cada uno de los caracteres que forman el texto que se está tratando y posteriormente a la extracción de un conjunto de características capaces de definir cada carácter aislado.
Una vez obtenido el vector de características de cada uno de los caracteres incluidos en el documento, se activa la etapa de reconocimiento que, en nuestro caso, consiste en una red neuronal que capaz de generar como salida el código ASCII de 8 bits del carácter cuyo vector de características recibe como entrada. Para que esto sea posible, previamente se ha sometido a la red neuronal a un proceso de aprendizaje (mediante el algoritmo backpropagation), en el cual se han utilizado documentos impresos conteniendo diferentes juegos de caracteres o abecedarios (todas las letras mayúsculas y minúsculas, los dígitos del "0" al "9" y signos de puntuación) con diferentes tamaños y tipos de letra (Courier. Arial, etc.). Durante este proceso se ajustan los parámetros internos de la red de forma reiterativa hasta que sea capaz de generar como salida el código ASCII del carácter cuya imagen se presenta a su entrada, para todas las formas y tamaños considerados para tal carácter.
2 AISLAMIENTO DE LOS CARACTERES
Para reconocer caracteres es necesaria, en primer lugar, su localización dentro del texto del documento, teniendo en cuenta, en esta operación el orden en el que se disponen en el mismo y los espacios en blanco y finales de línea, para que pueda recomponerse el texto tal y como se encontraba en el documento original.
Existen tres magnitudes que determinan el orden de los caracteres dentro de un texto: los renglones de los que consta, las palabras de un renglón y las letras de una palabra.
En este primer prototipo del sistema OCR, se han considerado las siguientes restricciones para facilitar la operación de aislamiento:
Teniendo en cuenta estas restricciones y considerando la imagen del texto como una matriz bidimensional en la que cada fila tiene un número de puntos igual al número de columnas (división que viene dada por la propia digitalización del documento), entonces las operaciones a realizar para localizar y separar renglones son las siguientes:
Un problema que se puede presentar en la separación de renglones es que aparezcan casos como el que se muestra en la figura siguiente:
es un niño pequeño
Para solucionar este problema se hace un procesamiento de cada uno de los posibles renglones de los que está compuesto el texto, de manera que si la altura de un renglón es menor que la mitad de la media de las alturas de los renglones detectados, y la distancia entre ese renglón y el siguiente es menor que 2/3 de la altura de este último, entonces se considera un "subrenglón" y se solapa con el siguiente. Se ha utilizado 2/3 de la altura en lugar de ½ como en [3
], porque se ha comprobado que se mejoran los resultados.Este procesamiento garantiza también la correcta detección de renglones de distinto tamaño en un mismo texto ya que, aunque la altura de un renglón sea menor que la media de los renglones, la distancia entre ese renglón y el siguiente, en general, es mayor que la altura de este último.
Una vez conocida la situación de los renglones y sus límites, se procede a aislar los caracteres. Como asumíamos inicialmente que no existiría solapamiento, se puede realizar una proyección vertical dentro de cada renglón para detectar los posibles caracteres. Esta proyección vertical da un resultado nulo en las zonas donde no existe tinta, lo que representa la separación entre dos caracteres, y resultados no nulos que indican la presencia de caracteres. Los límites en altura, superior e inferior, se detectan analizando la vertical de cada carácter, desde la parte superior e inferior, respectivamente, del renglón que lo contiene.
De esta forma, se consigue aislar cada carácter en una ventana rectangular con las dimensiones correspondientes su anchura y altura. Este método, además, es válido aún en el caso de existir caracteres de distinto tamaño dentro del mismo texto.
En cuanto a los caracteres "blancos" (espacios entre palabras), éstos se detectan cuando la separación entre dos caracteres consecutivos es mayor que 6/8 veces la altura del primero. En [3] se utiliza una relación de ½ veces la altura. Nosotros lo hemos ajustado a 6/8 ya que se mejoran los resultados. Por tanto, cuando se satisface esta condición, en realidad se ha localizado el final de una palabra, debiéndose considerar que a continuación de la misma hay un carácter "blanco" que habrá que tener en cuenta para una correcta recomposición del texto cuando se genere el fichero ASCII correspondiente al documento que se está reconociendo.
3 EXTRACCIÓN DE CARACTERÍSTICAS DE LOS CARACTERES
Después del aislamiento de los caracteres, se procede a la extracción de sus características. Aunque existen otros métodos, como la aplicación de transformada de Fourier, cálculo de momentos, obtención de finales de trazo, ángulos, cruces de trazos, etc., en este primer prototipo de sistema OCR se ha optado por dividir cada "ventana" resultante de aislar cada carácter, en ocho partes verticales por otras ocho horizontales, de tal forma que por cada carácter aislado obtenemos 64 valores representativos que constituyen el denominado vector (o matriz) de características de tal carácter. Mientras que en [3
] se proponen 25 valores, en nuestro caso, al trabajar con imágenes reales procedentes de un escáner, tal magnitud resulta insuficiente, por lo que, después de probar con diferentes tamaños, se ha adoptado el número de 64 por ser suficiente para diferenciar los caracteres.Las imágenes (ventanas) de los caracteres aislados están compuestas de un número de puntos de imagen o píxeles. Normalmente, este número no coincide con el número de parámetros (64) de su matriz de características. En tal situación pueden darse dos casos:
4 APRENDIZAJE Y RECONOCIMIENTO DE CARACTERES
CON UNA RED NEURONAL
Las Redes Neuronales son sistemas de computación que permiten la resolución de problemas que no pueden ser descritos fácilmente mediante un enfoque algorítmico tradicional, como, por ejemplo, ocurre en el reconocimiento de formas. Con las redes se expresa la solución de un problema, no como una secuencia de pasos, sino como la evolución de un sistema inspirado en el funcionamiento del cerebro y dotado, por tanto, de cierta "inteligencia". Tal sistema no es sino la combinación de una gran cantidad de elementos simples de proceso (nodos o neuronas) interconectados que, operando de forma masivamente paralela, consiguen resolver el problema [4
].Las conexiones sirven para transmitir las salidas de unos nodos a las entradas de otros. El funcionamiento de un nodo es similar al de las neuronas biológicas presentes en el cerebro. Suele aceptarse que la información memorizada en el cerebro está relacionada con los valores sinápticos de las conexiones entre las neuronas. De igual forma, se dice que las redes neuronales tienen la capacidad de "aprender" mediante el ajuste de las conexiones entre nodos. Estas conexiones tienen un valor numérico asociado denominado peso, que puede ser positivo (conexiones de excitación) o negativo (conexiones de inhibición).
Existen muchos tipos de redes neuronales, un modelo utilizado en una gran variedad de aplicaciones, entre las que se incluyen las de reconocimiento de formas [5][6], es la red multicapa con conexiones unidireccionales hacia delante (feedfoward). En la figura 2 se muestra la red de este tipo utilizada en el sistema OCR para el reconocimiento de caracteres.
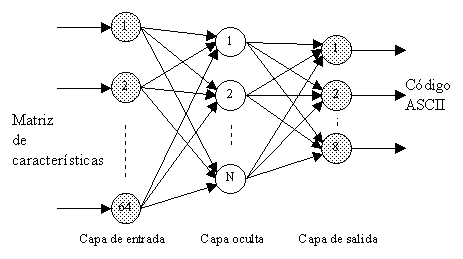
Figura 2.- Estructura de la red neuronal utilizada
En este tipo de estructura es posible distinguir una capa de entrada, varias capas de neuronas ocultas y una capa de salida. Cada una de las neuronas de la red recibe como entrada la suma de los valores de salida de las neuronas a ella conectadas multiplicados por el peso de la conexión correspondiente. Al resultado de esta suma se le aplica una función de transferencia (f) para obtener el valor que genera a la salida.
![]() 1
1
Una función de transferencia que habitualmente se utiliza en este tipo de redes es la denominada "sigmoidal":
y=f(x)=1/(1+e-q X)
Cuando se trabaja con redes neuronales como la que se utiliza en este trabajo, se distingue entre una primera etapa de aprendizaje o entrenamiento de la red y una segunda etapa de funcionamiento u operación de la red. En la primera se realiza el ajuste de los pesos en función de lo que se desea que almacene la red. Se suele distinguir entre dos tipos de aprendizaje: supervisado o no supervisado.
La red utilizada en el sistema de OCR, tiene un aprendizaje supervisado, el cual consiste en el ajuste de los pesos para que "aprenda" a relacionar un conjunto de patrones de entrada con las salidas que se desea que la red genere ante cada uno de dichos patrones. El entrenamiento concluye cuando la diferencia entre las salidas deseadas ante cada patrón y las que se obtienen realmente con los valores calculados de los pesos es suficientemente pequeña. A partir de este momento los pesos no varían y la red entraría en una fase operacional para cumplir la función que se desea de ella. Por ejemplo, si se va a utilizar para reconocimiento de caracteres, se supone que ha aprendido a distinguir entre diferentes tipos de imágenes de caracteres de entrada y a asociar a cada una un código ASCII.
Como se representó en la figura 2, la capa de entrada de la red utilizada consta de 64 neuronas que corresponden a los 64 valores (matriz de 8x8) que se extraen de la parametrización de un carácter. Se eligió este número para que las características extraídas fuesen lo suficientemente relevantes para distinguir unos caracteres de otros. Dado el tamaño de los caracteres en pixeles, una matriz menor podría dar lugar a mas confusión, una mayor sería redundante y emplearía un tiempo computacional mayor, aunque el límite final lo tenemos en la memoria disponible en el sistema.
En la capa oculta se pueden tener hasta 64 neuronas, las que en la de entrada. Se precisan más neuronas ocultas si el juego de caracteres que debe aprender la red es grande, para que el proceso de entrenamiento converja. Como se comentará en el apartado de resultados, con mas neuronas la red converge antes, además de cometer menos fallos en el reconocimiento, aunque en contrapartida, el hecho de tener más neuronas supone más de conexiones entre ellas y por tanto, debe hacer mayor número de operaciones empleando mas tiempo en cada ciclo de aprendizaje.
Por ejemplo, el aprendizaje de un alfabeto de 37 caracteres con un tipo de letra courier, con 12 neuronas ocultas converge en tan solo 20 iteraciones, reconociendo posteriormente un texto de prueba sin ningún fallo. Con 10 neuronas y los mismos parámetros de aprendizaje no lo hace en 60, y con 20 en 9 iteraciones.
En lo que se refiere a la capa de salida, como se pretende que la red genere el código ASCII de 8 bits del carácter que se presenta a la entrada, se necesitan 8 neuronas con salida binaria. Otra posible estructura de salida, aunque no se ha implementado aquí, podría utilizar tantas neuronas de salida como caracteres a reconocer, es decir una salida para cada tipo de carácter del alfabeto que se quiera utilizar.
El algoritmo de aprendizaje que se ha utilizado para "enseñarle" a la red los caracteres, es el de retropopagación de gradiente o Backpropagation [7].
5 SOFTWARE DESARROLLADO.
El programa desarrollado ofrece un menú principal con las siguientes opciones:
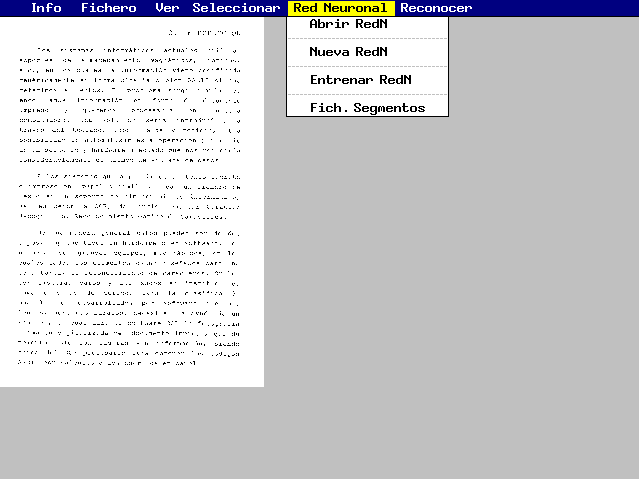
Figura 3.- Imagen de un documento y funciones relacionadas con las redes neuronales.
La opción Fich. segmentos permite crear y modificar ficheros para el aprendizaje de las redes, donde se almacenan tanto las (64) características extraídas de cada carácter como su código ASCII (8 bits). A partir de la imagen de un documento, se puede decidir añadir información a un fichero de entrenamiento de dos formas posibles: manual, aislando cada posible carácter de la imagen e introduciendo directamente por teclado el carácter que representa; o de forma automática, considerando que la imagen representa un alfabeto previamente definido, compuesto por los 73 caracteres siguientes:
abcdefghijklmnñopqrstuvwxyzABCDEFGHIJKLMNÑOPQRSTUVWXYZ0123456789áéíóú.,:;
Si se ha seleccionado una red neuronal y un fichero de entrenamiento, se puede proceder al aprendizaje. El programa (opción Entrenar) aplica el algoritmo Backpropagation, presentando un cuadro que indica como va evolucionando el entrenamiento: nº de ciclos de entrenamiento, desviación máxima entre salidas actuales y salidas deseadas y error cuadrado medio que se comete para todas las salidas (figura 4). El proceso se interrumpe cuando se pulsa una tecla o cuando se alcanzan los tres mil ciclos.
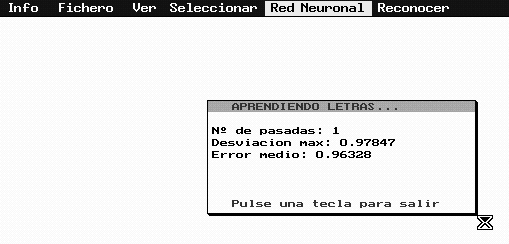
Figura 4.- Proceso de aprendizaje de caracteres.
6 RESULTADOS.
Para valorar el funcionamiento del sistema, se comenzó utilizando un alfabeto compuesto por 37 caracteres (minúsculas y números) con los tres tipos de letra más comunes para, posteriormente ampliarlo a 73 (añadiendo mayúsculas, vocales acentuadas y signos de puntuación) como se representa en la figura 5.
ARIAL: abcdefghijklmnñopqrstuvwxyz0123456789
COURIER: abcdefghijklmnñopqrstuvwxyz0123456789
TIMES: abcdefghijklmnñopqrstuvwxyz0123456789
COURIER (73 caracteres): abcdefghijklmnñopqrstuvwxyz ABCDEFGHIJKLMNÑOPQRSTUVWXYZ0123456789áéíóú . , : ;
Figura 5.- Patrones de entrenamiento
Durante las pruebas se comprobó que al aumentar el número de patrones de entrenamiento, con varias muestras de un mismo carácter (del mismo tipo de font), aunque aumenta el tiempo de presentación de todos ellos a la red, sin embargo, el tiempo de convergencia del aprendizaje se reduce considerablemente (le "cuesta" menos aprender) y los resultados de la fase de reconocimiento son mejores. Por esta razón, y puesto que el procedimiento de aislamiento y extracción de características aplicado, mediante una ventana que se ajusta al tamaño del carácter hace que las características que se extraen de él no dependan de su tamaño, se procedió a entrenar la red con distintos tamaños de cada carácter, puesto que ello no era sino "enseñarle" el mismo carácter, de tamaño único, pero con pequeñas variaciones y, por tanto, ayudaba a la convergencia de la red y a mejorar los resultados obtenidos.
Se probaron redes con diferente número de neuronas ocultas (desde 12 hasta 60) y diferentes valores para los parámetros de entrenamiento (tasa de aprendizaje y tasa de momento), observándose que además de aumentar el tiempo de aprendizaje al incrementar el número de patrones de entrenamiento, también se requerían más neuronas ocultas para aumentar la capacidad de aprendizaje de la red. El uso de distintos parámetros de aprendizaje mostró que para ciertos valores de éstos la red converge adecuadamente y los resultados son satisfactorios. Generalmente los valores altos no garantizaban un funcionamiento del todo correcto.
Utilizando los tres tipos de letra antes citados en el reconocimiento de texto diferente al utilizado durante la fase de entrenamiento, se han obtenido porcentajes de acierto del orden del 98 al 100% de los caracteres, siempre que en estos documentos los tipos de letra sean los incluidos en los alfabetos "aprendidos" por la red. Esto, sin embargo, no le resta generalidad al funcionamiento de la red, ya que hay que tener en cuenta que, a pesar de ser caracteres del mismo tipo, al haber sido capturado el texto mediante un escáner, se ha introducido ruido y su digitalización normalmente es diferente, por lo que las imágenes reales del mismo carácter en el texto de entrenamiento y en el de prueba son diferentes, siendo capaz la red de determinar que se trata en ambos caso del mismo símbolo ASCII. Los mejores resultados se han obtenido utilizando alfabetos con 5 tamaños de letra diferentes y un número elevado de neuronas ocultas (entre 30 y 60), alcanzándose la convergencia en el aprendizaje en menos de 1000 iteraciones.
El hecho de caracterizar cada carácter con una ventana que se ajusta a él, ofreciendo el sistema invarianza respecto a su tamaño, plantea un problema para patrones de entrenamiento en los que se incluyen mayúsculas y minúsculas, puesto que hay ciertos caracteres que son muy parecidos en estas dos formas. Cuando ocurre esto, puede suceder que se le esté exigiendo a la red que para dos entradas iguales genere dos salidas diferentes, con la consiguiente no convergencia del aprendizaje. No obstante, siempre existen diferencias debido al ruido introducido en el proceso de digitalización de la imagen de los documentos, de ahí que, a pesar de todo, se hayan obtenido buenos resultados.
También se hicieron pruebas con caracteres manuscritos, pero los resultados no fueron buenos ya que una misma letra varía demasiado de una realización a otra. La red aprendió muy bien los patrones de entrenamiento pero cometía errores al reconocer un texto de prueba debido a la diferencia entre sus caracteres y los del entrenamiento.
7 CONCLUSIONES Y TRABAJO FUTURO
Inicialmente, con este trabajo se pretendía desarrollar un prototipo software que, en primer lugar, permitiera trabajar con imágenes reales de documentos y, en segundo lugar, realizara una primera aproximación al proceso del reconocimiento del texto incluido en tales documentos utilizando la tecnología de las redes neuronales. Ambos objetivos han sido cumplidos, ofreciendo un punto de partida para posteriores refinamientos y mejoras de los métodos utilizados, entre lo que podrían contemplarse lo siguientes:
8 REFERENCIAS Y BIBLIOGRAFÍA
Para introducirse y profundizar el tema de sistemas OCR, se recomienda la lectura de [8] y de la revista IEEE Transactions on Pattern Analysis and Machine Intelligence.
[1] Maravall, D. "Reconocimiento de Formas y Visión Artificial". RA-MA, 1993.
[2] Romero, J.P. "Sistema Reconocedor de Caracteres". Escuela Universitaria Politécnica. Universidad de Alcalá de Henares, 1996.
[3] Delgado, S. "Un Sistema de Reconocimiento de Caracteres Impresos". Escuela Universitaria de Informática. Universidad Politécnica de Madrid, 1990.
[4] Hilera, J.R.; Martínez, V.J. "Redes Neuronales Artificiales". RA-MA, 1995.
[5] Arroyo, F; Gonzálo, A; Hilera, J.R. "Using Artificial Neural Networks for Ultrasonic Signals Processing from Simple Geometric Shapes", en el libro "From Natural to Artificial Neural Computation" (J. Mira & F. Sandoval eds.), Springer-Verlag, pp. 987-991, 1995.
[6] Hilera, J.R.; Martínez, V.J.; Mazo, M. "ECG Signals Processing with Neural Networks", International Journal of Uncertainity, Fuzziness and Knowledge-Based Systems, Vol. 3, No. 4, pp. 419-430, 1995.
[7] Rumelhart, D.E. "Learning Representations by Back-Propagating Errors", Nature, 323, pp. 533-536, 1986.
[8] Pavlidis, T.; Mori, S. (eds) "Special Issue on Optical Character Recognition", Proceedings of the IEEE, Vol. 80, No. 7, July, 1992.